In my previous blog post, I talked about how to recover from a failed Kubernetes node by manually deleting the machine object. TL;DR of this article is that you can offload this remediation to Kubernetes itself by “machine health check” resources. But first let’s talk about some concepts of Cluster API to better understand the process and what that means to TKGs (Tanzu Kubernetes Grid Service).

Cluster API is a Kubernetes sub-project focused on providing declarative APIs and tooling to simplify provisioning, upgrading, and operating multiple Kubernetes clusters. Started by the Kubernetes Special Interest Group (SIG) Cluster Lifecycle, the Cluster API project uses Kubernetes-style APIs and patterns to automate cluster lifecycle management for platform operators. The supporting infrastructure, like virtual machines, networks, load balancers, and VPCs, as well as the Kubernetes cluster configuration are all defined in the same way that application developers operate deploying and managing their workloads. This enables consistent and repeatable cluster deployments across a wide variety of infrastructure environments.
Generally speaking, Cluster API Provider for vSphere (CAPV) is an implementation of Cluster API (CAPI) for vSphere environments. With TKGs, what we see as CAPW controller is another abbreviation that stands for Cluster API for Workload Control Plane (WCP). WCP is how VMware engineers refer to the capability enabled through the Supervisor Cluster. The CAPW controller is the infrastructure specific implementation of Cluster API.
In order to properly understand the concept of Cluster API, we need to define a few components in the first place;
- Management Cluster: A Kubernetes cluster that manages the lifecycle of Workload Clusters. A Management Cluster is also where one or more Infrastructure Providers run, and where resources such as Machines are stored. With TKGs, this is Supervisor Cluster itself, a cluster that is enabled for vSphere with Tanzu. It runs on top of an SDDC layer that consists of ESXi for compute, NSX-T Data Center or vSphere networking, and vSAN or another shared storage solution.
- Workload Cluster: A guest Kubernetes cluster whose lifecycle is managed by a Management Cluster, this is what we see as TKC (Tanzu Kubernetes Cluster) within namespaces in Supervisor Cluster.
- Infrastructure Provider: A source of computational resources, such as compute and networking. For example, cloud Infrastructure Providers include AWS, Azure, and Google, and bare metal Infrastructure Providers include VMware, MAAS, and metal3.io.
- Control Plane: The control plane is a set of services that serve the Kubernetes API and continuously reconcile desired state using control loops. With TKGs, dedicated machine-based control planes are provisioned in order to run static pods for components like api-server, controller-manager and kube-scheduler.
There are also many Custom Resource Definitions (CRDs) in Kubernetes related with core Cluster API and these are the ones that makes most sense;
- Machine: A “Machine” is the declarative spec for an infrastructure component hosting a Kubernetes Node (a VM in our scenario). If a new Machine object is created, CAPW controller will provision and install a new host to register as a new Node matching the Machine spec. From the perspective of Cluster API, all Machines are immutable; once they are created, they are never updated (except for labels, annotations and status), only deleted. For this reason, MachineDeployments are preferable. MachineDeployments handle changes to Machines by replacing them, in the same way core Deployments handle changes to Pod specifications.
- MachineDeployment: A MachineDeployment provides declarative updates for Machines and MachineSets.
- MachineSet: A MachineSet’s purpose is to maintain a stable set of Machines running at any given time.
- MachineHealthCheck: A MachineHealthCheck defines the conditions when a Node should be considered unhealthy. If the Node matches these unhealthy conditions for a given user-configured time, the MachineHealthCheck initiates remediation of the Node. Remediation of Nodes is performed by deleting the corresponding Machine.
And this is the workflow showing how the process works;

For more information, please refer to The Cluster API Book.
MachineHealthCheck in action
After this long introduction to the basic concepts of Cluster API and MachineHealthCheck, let’s implement our manifest and see it in action.
- Login to Supervisor Cluster with an authorized sso account. Even if you have edit role on your namespace (this will correspond to “edit” ClusterRole in Supervisor Cluster), you won’t have enough privileges to create MachineHealthCheck resource, so please refer to this post to overcome this.
- Save the following YAML manifest on your filesystem, modify according to your cluster and create your MachineHealthCheck resource in the namespace where your TKC resource resides. This resource will make the machine health check controller initiate the remediation process after 5 minutes of node failure.
kubectl apply -f your-manifest.yaml -n your-namespace
apiVersion: cluster.x-k8s.io/v1alpha3
kind: MachineHealthCheck
metadata:
name: node-unhealthy-5m
spec:
clusterName: tkc0804121533
maxUnhealthy: 50%
nodeStartupTimeout: 10m
selector:
matchLabels:
machine-template-hash: "3675602100"
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
# * clusterName is required to associate this MachineHealthCheck with a cluster.
# * (Optional) maxUnhealthy prevents further remediation if the cluster is
# already partially unhealthy.
# * (Optional) nodeStartupTimeout determines how long a MachineHealthCheck should
# wait for a Node to join the cluster, before considering a Machine unhealthy.
# * selector is used to determine which Machines should be health checked.
# * unhealthyConditions to check on Nodes for matched Machines, if any condition
# is matched for the duration of its timeout, the Machine is considered unhealthy.
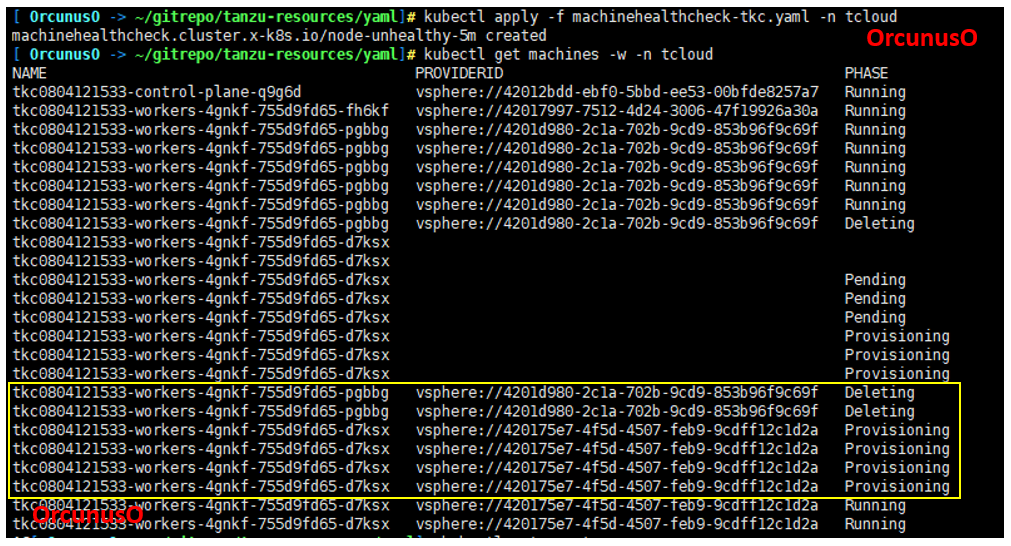
- Now, trigger a node failure and watch the machine health check controller remediates it after given user-configured time by deleting and re-creating a machine resource along with the virtual machine resource in vSphere. The node should be listed as “Ready” after remediation.
Final Comments
According to Tanzu Kubernetes Grid 1.2 documentation, this feature is enabled in the global TKG configuration by default, for all Tanzu Kubernetes clusters. But this doesn’t seem to be the case for TKGs, at least for now.
